Imperfect multicollinearity occurs when two or more explanatory variables in a statistical model are correlated with each other, but not perfectly.
That’s the gist of it. To get a full explanation of imperfect multicollinearity, keep reading:
#1) Imperfect Multicollinearity Definition
Multicollinearity occurs when the explanatory variables in a regression model are correlated with each other, which leads to excessive variance and unstable estimates of the regression coefficients.
So, what’s the difference between perfect and imperfect multicollinearity?
Perfect multicollinearity is worse than imperfect multicollinearity.
Unlike imperfect multicollinearity, perfect multicollinearity prevents the OLS estimator from being calculated.
The OLS (Ordinary Least Squares) is a method analysts use to estimate the parameters of a multiple regression model.
In general, you want to see the OLS estimator follow a set of assumptions called the Gauss-Markov theorem.
Among the assumptions in this theorem that guarantee the estimator is the best, there’s the assumption of no perfect multicollinearity.
This assumption says the predictor variables are not perfectly correlated with each other. A predictor variable is also called an independent variable, regressor, or explanatory variable.
If there is perfect multicollinearity (at least two variables are perfectly correlated), the OLS estimator is not unique and cannot be calculated.
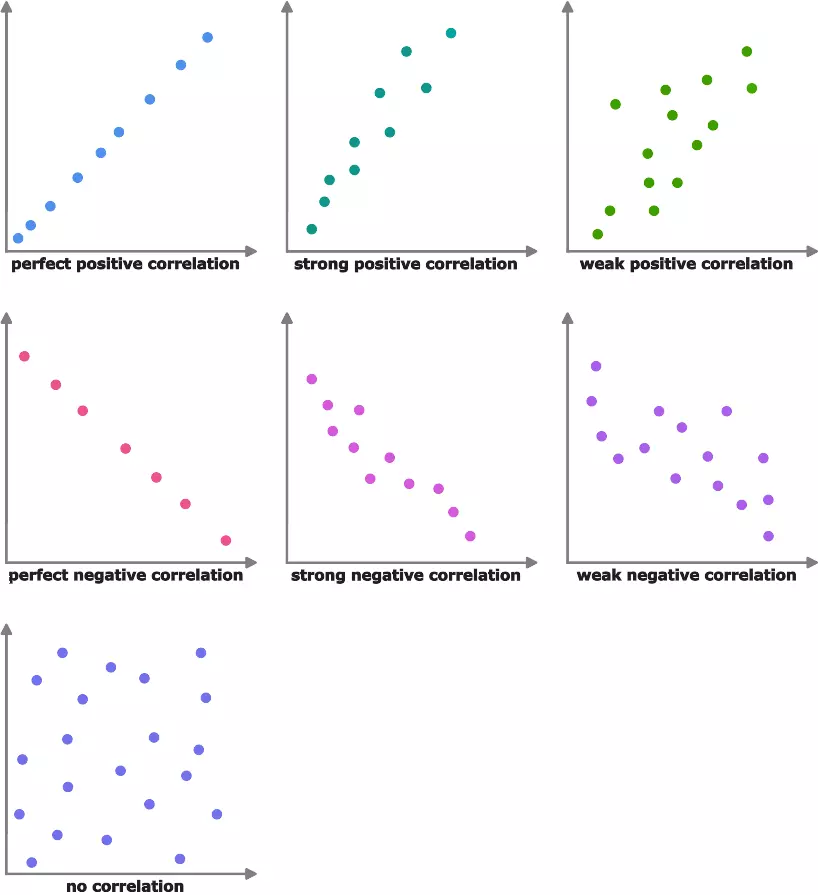
In contrast, under imperfect multicollinearity some explanatory variables are correlated with each other. But it is not a perfect correlation (1 or –1).
This does not prevent the calculation of the OLS estimator, but it can cause problems:
#2) Imperfect Multicollinearity Consequences
Imperfect multicollinearity implies that it will be difficult to interpret the results of the model. Therefore, the main consequences of imperfect multicollinearity are:
- Unstable and inconsistent estimates: The estimated values of the parameters can vary a lot every time you change the sample. This makes it difficult to accurately interpret the results of the linear relationship model.
- Higher variance: This results in wider confidence intervals, meaning larger uncertainty around the estimated values. The problem? It’s harder to draw conclusions from the model.
In general, when a data set has multicollinearity, coefficient estimators are less efficient. What does this mean? They have higher variance and lower precision than if there was no collinearity between variables. As a result, estimates are imprecise and questionable (although not necessarily biased).
#3) How to Detect Imperfect Multicollinearity
So how do you identify and test multicollinearity in a model?
Here are a few ways to identify imperfect multicollinearity:
- Correlation matrix: Examine the correlation matrix of your variables. Look for pairs of independent variables with high correlation (generally a correlation coefficient of 0.8 or higher).
- Variance inflation factor (VIF): Check the VIF. This measures how much the variances of the estimates are inflated due to multicollinearity. A VIF above 10 is a high variance inflation factor and is generally a sign of multicollinearity.
- Standard errors of the estimates: Look at the standard error of the estimates of each regression coefficient. If the standard errors are big compared to the estimates, this can signal multicollinearity.
To get a complete picture of the multicollinearity in your data (whether it’s time series or cross-sectional data), it’s best to use a combination of these approaches.
If you detect multicollinearity in your data, it’s a good idea to address it and ensure your statistical model is stable and accurate:
#4) How to Address Imperfect Multicollinearity
There are several approaches you can take to mitigate the effects of imperfect multicollinearity in regression analysis. Here are a few options to consider:
- Remove one of the correlated variables from the model.
- Transform the variables. For example, take the logarithm of one explanatory variable, or multiply it by a dummy variable to create a new one.
- Use ridge regression or LASSO (Least Absolute Shrinkage and Selection Operator), as these are two methods specifically designed to deal with multicollinearity in statistical models.
- Use a method that is not sensitive to multicollinearities like the OLS regression is, such as decision trees, random forests, and neural networks.
Do not simply ignore the problem of multicollinearity and assume it won’t affect your results.
However, you must avoid removing a certain kind of included variable:
#5) Imperfect Multicollinearity and Omitted Variable Bias
If you decide to remove or transform one of the correlated variables from your model to address the multicollinearity, you need to be careful about which variable you choose.
Removing the wrong variable changes the interpretation of the results, and leads to omitted variable bias.
Omitted variable bias is when a relevant predictor variable is left out of a statistical model. If an important variable is not accounted for, the model is questionable.
To avoid omitted variable bias, always consider:
- The contribution to the multicollinearity: Eliminate the variables that contribute the most to the multicollinearity. As long as it’s not a variable that—if removed—causes the model to lose its meaning.
- The importance of the variable: As mentioned above, removing a variable that is very relevant to the outcome of the model is more likely to cause omitted variable bias than removing a less important variable.
#6) Imperfect Multicollinearity Example
Here are two examples of imperfect multicollinearity:
Imagine you want to predict how tall a person is on two other variables.
Your initial assumption is that taller people are older and heavier, so you include age and weight as variables in your model.
However, if age and weight are correlated with each other (for example, older people are generally heavier), then you might have imperfect multicollinearity in your model.
Now, how can this make it difficult to interpret the results of your linear regression model? Because it’s hard to know which variable (age or weight) has the biggest impact on the outcome (height, the dependent variable).
Another example:
Let’s say you want to predict stock prices.
A wide range of factors influence stock prices, such as earnings, general economic indicators, and market conditions.
These predictor variables are likely correlated with each other. How do you know which has the biggest impact on stock prices?
In general, it’s best to avoid imperfect multicollinearity in statistical models because it can lead to confusion. However, most times you can’t avoid it.
What can you do? Be careful when interpreting the results of your model.
Imperfect Multicollinearity FAQs
What is the problem with imperfect multicollinearity?
The problem with imperfect multicollinearity in OLS is that it results in inconsistent parameter estimates that have high variance, meaning they change a lot with different samples, and make it harder to draw accurate conclusions about the model. Perfect multicollinearity is worse though.
How can you detect imperfect multicollinearity?
The main way to detect multicollinearity is to test the correlation between different pairs of independent variables and look for high values.
Does imperfect multicollinearity cause bias?
No, imperfect multicollinearity does not directly cause bias in statistical modeling. Imperfect multicollinearity produces parameter estimates that are unstable and inconsistent, making it hard to understand the model’s findings. You can solve this by removing a variable that contributes a lot to multicollinearity. However, if you remove a variable that is important to the model’s intention, it leads to omitted variable bias.
